
做网站优化的人都知道,robots.txt文件是告诉搜索引擎,那些可以抓取,那些不能抓取,今天,我们来系统讲讲robots.txt文件那些事情。
如何通过Robots协议屏蔽搜索引擎抓取网站内容?
Robots协议(也称为爬虫协议、机器人协议等)的全称是网络爬虫排除标准(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。避免出现网站被爬虫访问,导致耗费大量流量和宽带的问题。
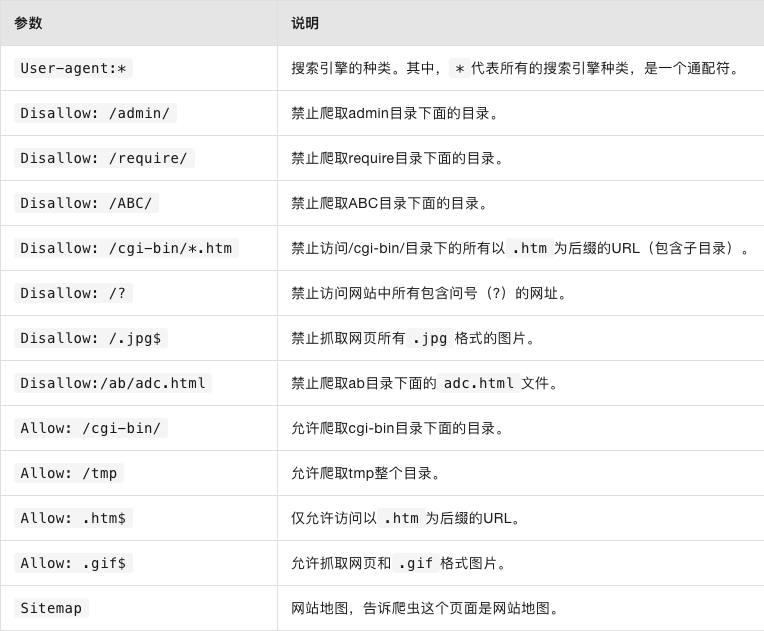
robots.txt文件的参数配置说明
如果有些网站页面访问消耗性能比较高,不希望被搜索引擎抓取,您可以在站点根目录下存放robots.txt文件,屏蔽搜索引擎或者设置搜索引擎可以抓取文件的范围以及规则
robots.txt文件的参数配置说明如下:
Robots协议不是强制协议,通过robots.txt文件能够保护您的一些文件不暴露在搜索引擎之下,从而有效地控制爬虫的抓取路径。但是,部分搜索引擎或者伪装成搜索引擎的爬虫不会遵守该协议,对于不遵守该协议的情况,以下处理方法无效。
操作示例
本部分以下面场景为例,为您展示通过Robots协议屏蔽搜索引擎抓取网站内容的方法,操作示例如下所示。
示例一:执行以下命令,禁止所有搜索引擎访问网站的任何资源。
User-agent: *
Disallow: /
示例二:执行以下命令,允许所有搜索引擎访问任何资源。
User-agent: *
Allow: /
说明:您也可以建一个/robots.txt空文件,将Allow的值设置为/robots.txt。
示例三:执行以下命令,禁止某个搜索引擎(例如Google)访问网站。
User-agent: Googlebot
Disallow: /
示例四:执行以下命令,允许某个搜索引擎(例如Baidu)访问网站。
User-agent: Baiduspider
allow: /
示例五:执行以下命令,禁止所有搜索引擎访问特定目录。
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /data/
示例六:执行以下命令,允许访问特定目录中的部分URL,实现a目录下只有b.htm允许访问。
User-agent: *
Allow: /a/b.htm
Disallow: /a/
关于关于网站robots.txt文件那些事情,我们就简单介绍这些,希望对你有帮助。